Table of contents
| Introduction | What is KFLAT |
| How KFLAT works | Overview of the KFLAT operation |
| KFLAT internals | Interesting details from KFLAT implementation |
| KFLAT use cases | How KFLAT can be helpful |
| Recipe generation | Automatic preparation of KFLAT recipes |
| UFLAT | KFLAT for user space memory |
| Summary | Final conclusions |
| References | Click here for more information |
Introduction
KFLAT - short for kernel flattening - is an open source tool for serializing Linux kernel variables or function parameters and restoring them in any application, especially in C user space applications. KFLAT achieves that by hooking into selected target kernel function, obtaining a reference to the interesting variable (either global variable or function parameter), copying its content and following all the pointers in the dumped area that could lead us to more dependend memory regions.
It sounds a bit simple, just making a few memory copies but in reality it becomes a very difficult task since most of the kernel structures are really huge. For instance very commonly used kernel structure, i.e. the task_struct kernel structure that holds the data for the Linux kernel process implementation has more than three thousand dependencies (i.e. other structures reachable through various pointers). So basically if you would like to copy task_struct definition into new C project you would need to copy 3k other structures as well for the code just to compile. This is the scale that need to be dealt with. Moreover the kernel code contains various patterns like implementing linked lists through list_head type, constructing trees, accessing embedding types for specific pointers using container_of etc. which also need to be handled accordingly.

Figure 1. High-level KFLAT operation
Once we deal with all the code related aspects we end up with an easy to use and portable memory dump. Such memory dump can be then loaded or mapped into a new application into new virtual address space and used like any other C memory. What we could use it for then? We can use it for fast memory initialization. For instance we can dump some memory from a normally running system and use it as an initial corpus for fuzzer. We can use it for debugging as we can dump some internal kernel structures and then view them in user space just like with kgdb except that we don't have to recompile the whole kernel with CONFIG_KGDB enabled or use any additional hardware. Finally we can use it for info or statistics gathering as we can extract new metrics from the kernel by accessing its internal structures and viewing them in user space.
How KFLAT works
Let's now take a look into more details how KFLAT actually works. We call the process of memory serialization by the term flattening, because under the hood KFLAT flattens a huge part of intertwined memory regions into a single continuous memory blob. It's best explained based on a very simple example.
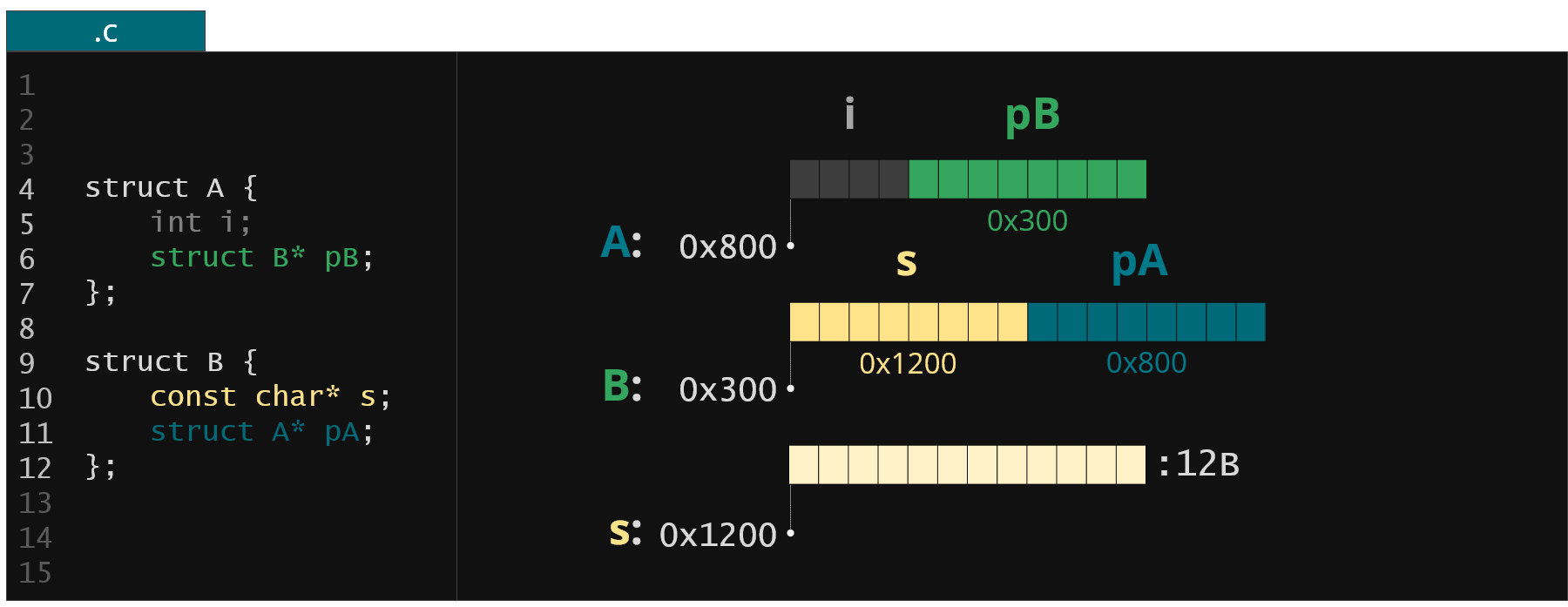
Figure 2. Example of memory representation for simple C structures
On the left we have two structures - struct A with a pointer to struct B object and struct B with pointer to some string and pointer back to struct A object. On the right we have an example representation of these two structures in the kernel memory. When the KFLAT starts its journey it collects all the memory regions it can find by following all the pointers. It then sorts them in ascending orders of memory addresses.
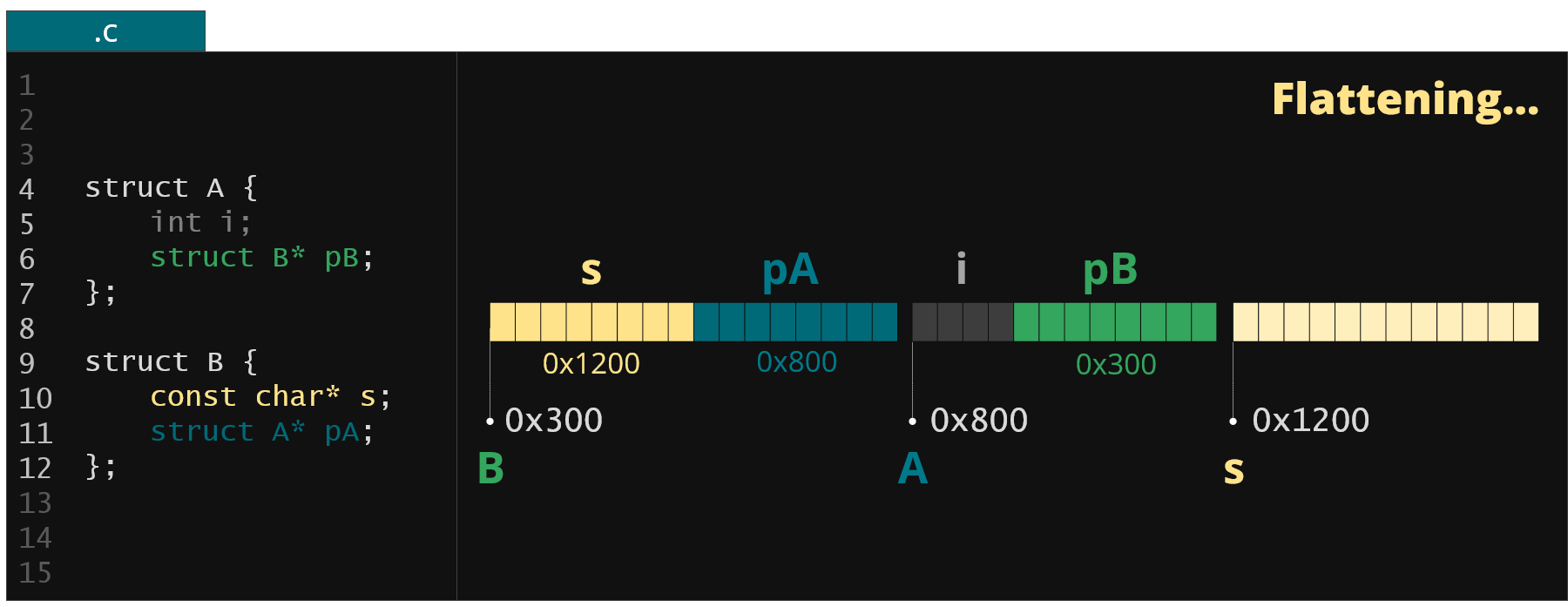
Figure 3. Sorted memory regions for example from Fig. 2
Finally it flattens them into a single continuous blob and replaces all the pointers in this blob with proper offsets to point to the same memory regions as in the original memory area. This way we end up with a small, portable and easy to move memory representation.
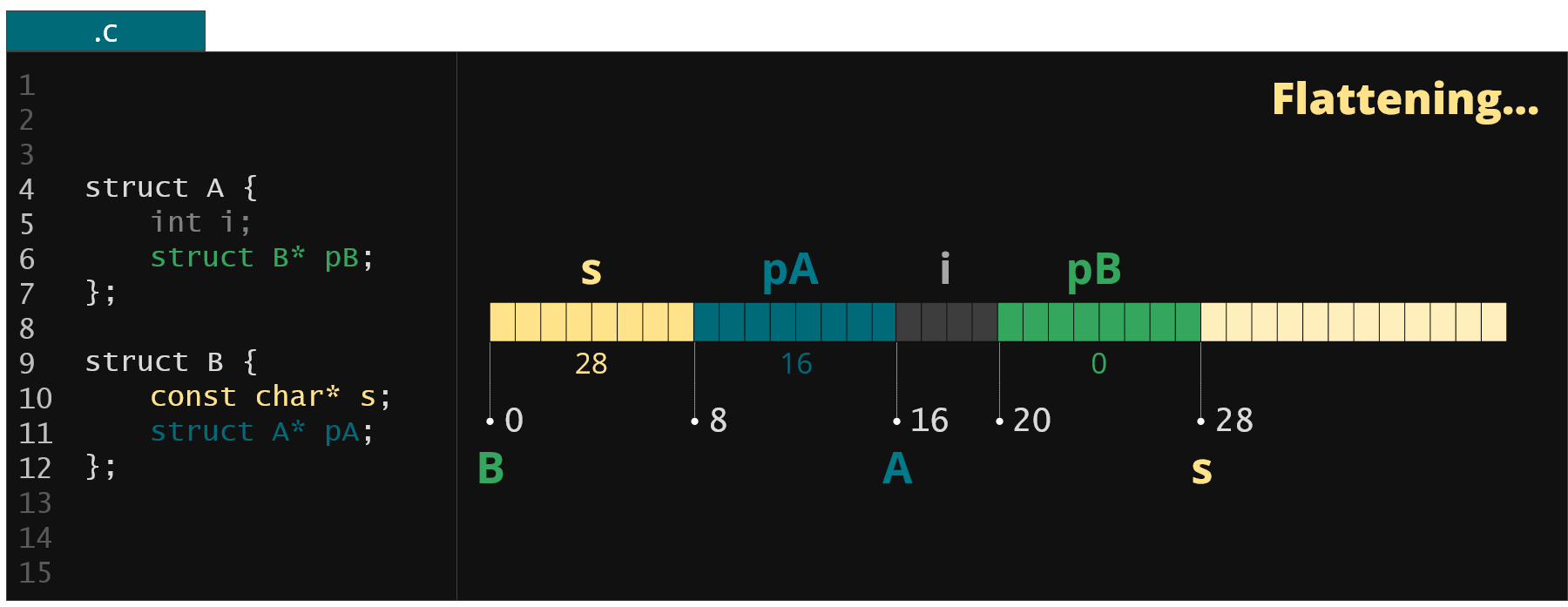
Figure 4. Continuous memory region with resolved pointer values created by KFLAT
To restore this memory in the user space process all we need to do is to load this memory image into a new address space at some address X and fix all the pointers (offsets) that are stored in the image file with pointers from this new address space.
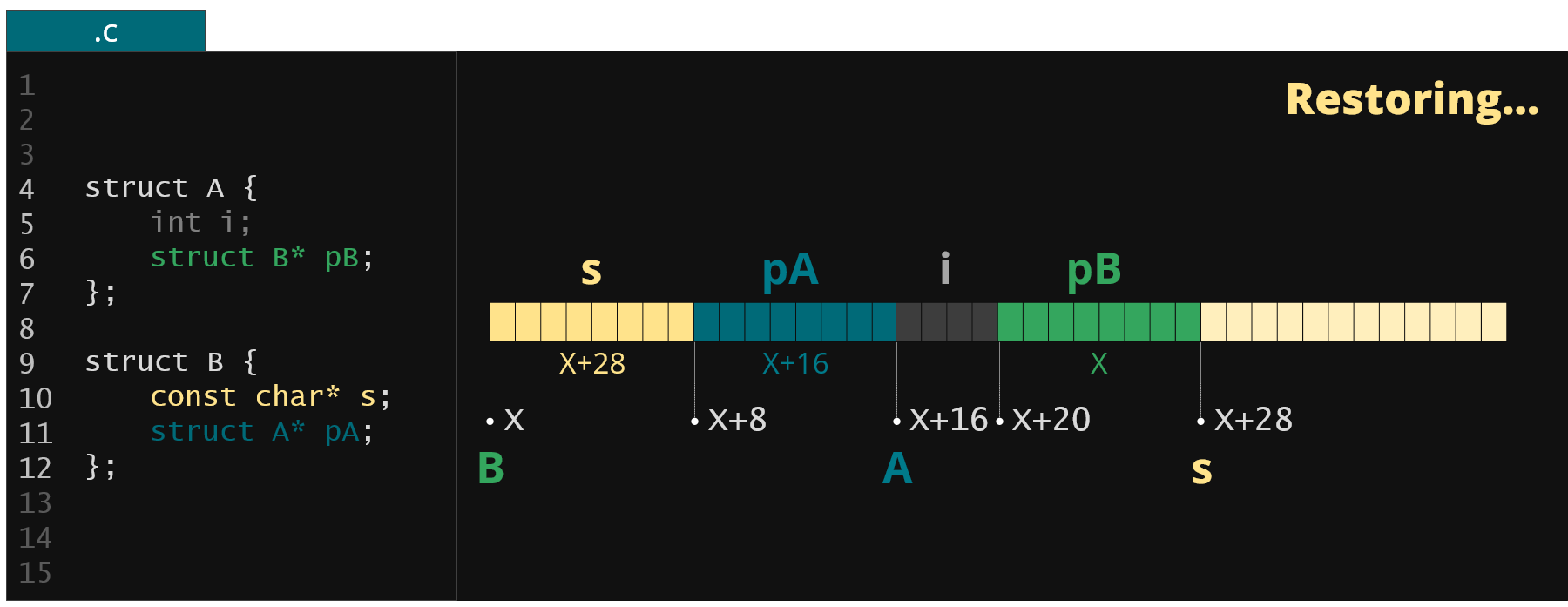
Figure 5. Restoration process of the KFLAT image in user-space application
Finally we obtain a reference to our initial structure (struct A) so we can have some entry point to this dumped memory region. This way you could end up with the same memory in your application as in the original target. Moreover you could use this memory like any other C memory.
You could now ask, how the KFLAT knows where are the pointers in the original memory structures? This is a quite tricky task since in C we have no run type information like in C++ or Golang or other higher level languages, also pointers in C are a bit imprecise:
- we can have a pointer to void that basically can point to anything (member p in the example below)
- we can have a pointer to integer that can point to a single integer or an array of integers (member a in the example below)

Figure 6. Examples of pointer ambiguities in C programming language
Basically pointers in C are just numbers that can point to anything and can be anywhere in the structure. To alleviate that KFLAT uses recipes, so called KFLAT recipes which precisely describe the content of the structures being dumped, in particular where exactly the pointer members are located within the structures. Moving back to our previous example with two simple structures the KFLAT recipes look like follows.

Figure 7. KFLAT recipes from example from Fig. 2
We have a member pB in the struct A that points to the instance of the struct B. We provide an AGGREGATE_FLATTEN_STRUCT recipe that describes exactly that. Similarly the recipe for the struct B tells us that the member pA points to the instance of struct A and also the s member points to a C-string (AGGREGATE_FLATTEN_STRING recipe). That way the KFLAT engine can precisely dump the memory and preserve all the memory layout.
Let's now take a look at a bit more complicated example being an interval tree. Let's imagine we created an interval tree in the kernel memory that holds information about all the virtual memory regions that are allocated in the kernel. Under the hood the search interval tree would be implemented using red black trees (as described in the below example).
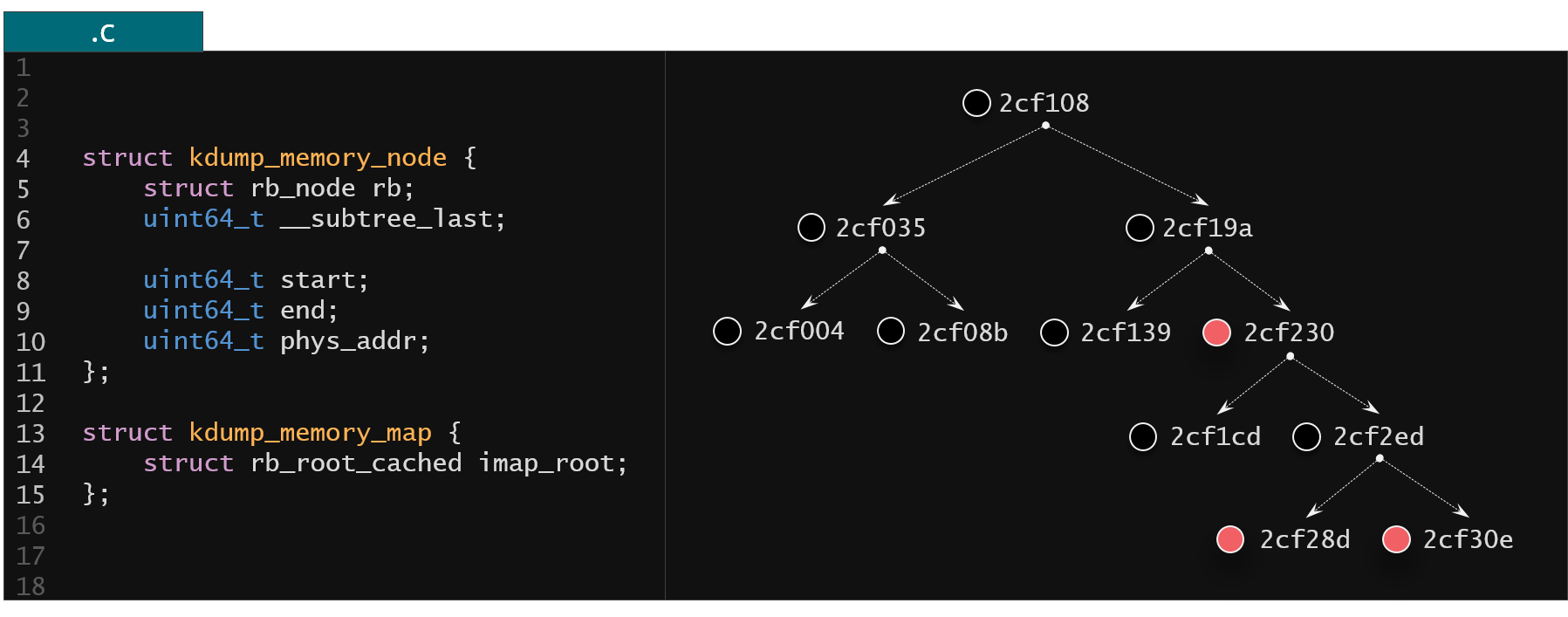
Figure 8. Interval tree kernel implementation using the red-black trees
With only a few lines of code (presented below) KFLAT can dump this memory without any problem for the interval tree having 600k different intervals.

Figure 9. KFLAT recipes for the interval tree kernel structures
The produced image have something around 32 megabytes so it's quite portable and the flattening process takes just a few milliseconds so it's almost instantaneous.
KFLAT internals
Let's now see in more details how KFLAT works under the hood.
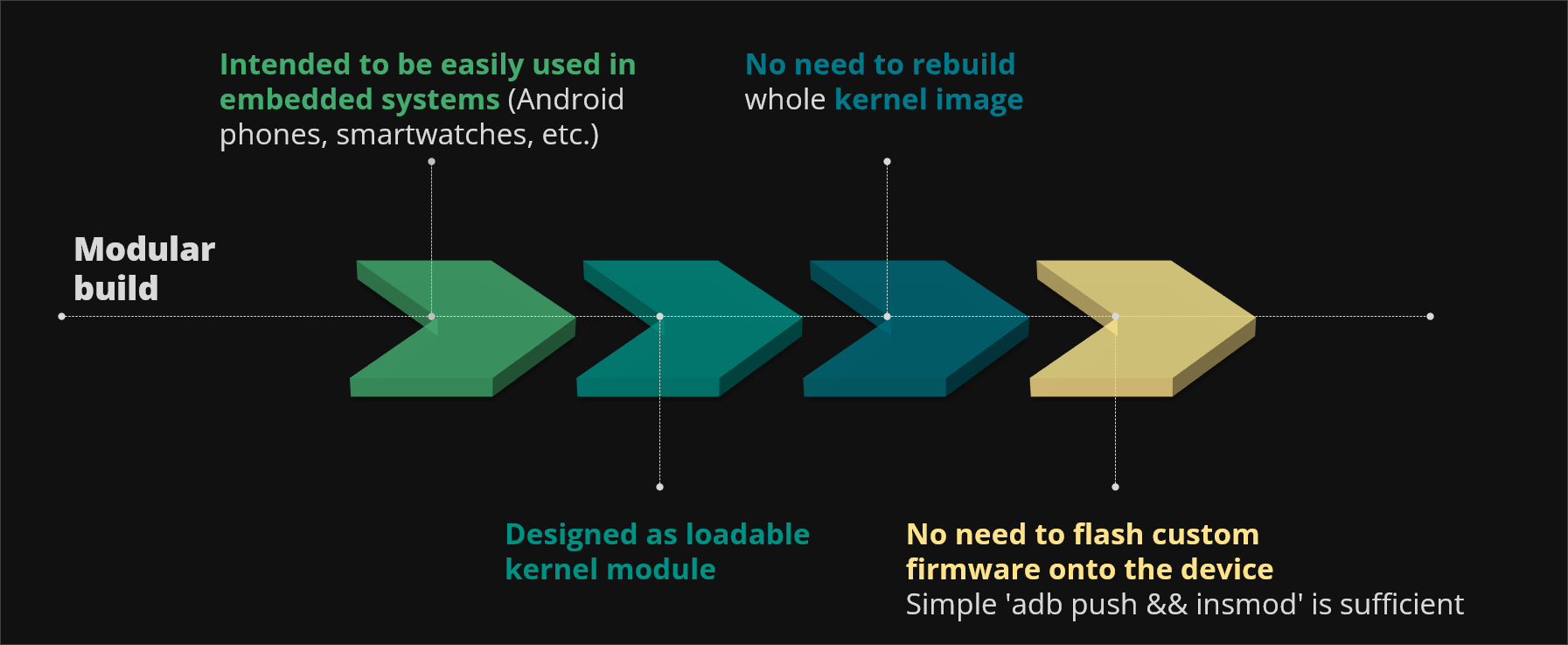
Figure 10. KFLAT modular build
From the very beginning our goal was to use KFLAT on embedded systems like smartphones, smart watches, Android devices or IoT devices and that's why we implemented KFLAT as a loadable kernel module. That way we don't need to rebuild the whole kernel image every time we want to change some part of KFLAT implementation. We can simply build KFLAT, push it onto the target device and load it into the kernel. Moreover the KFLAT recipes that describe all the structure layouts are built as kernel modules as well so we can hot plug them into the running system at any time in the execution.
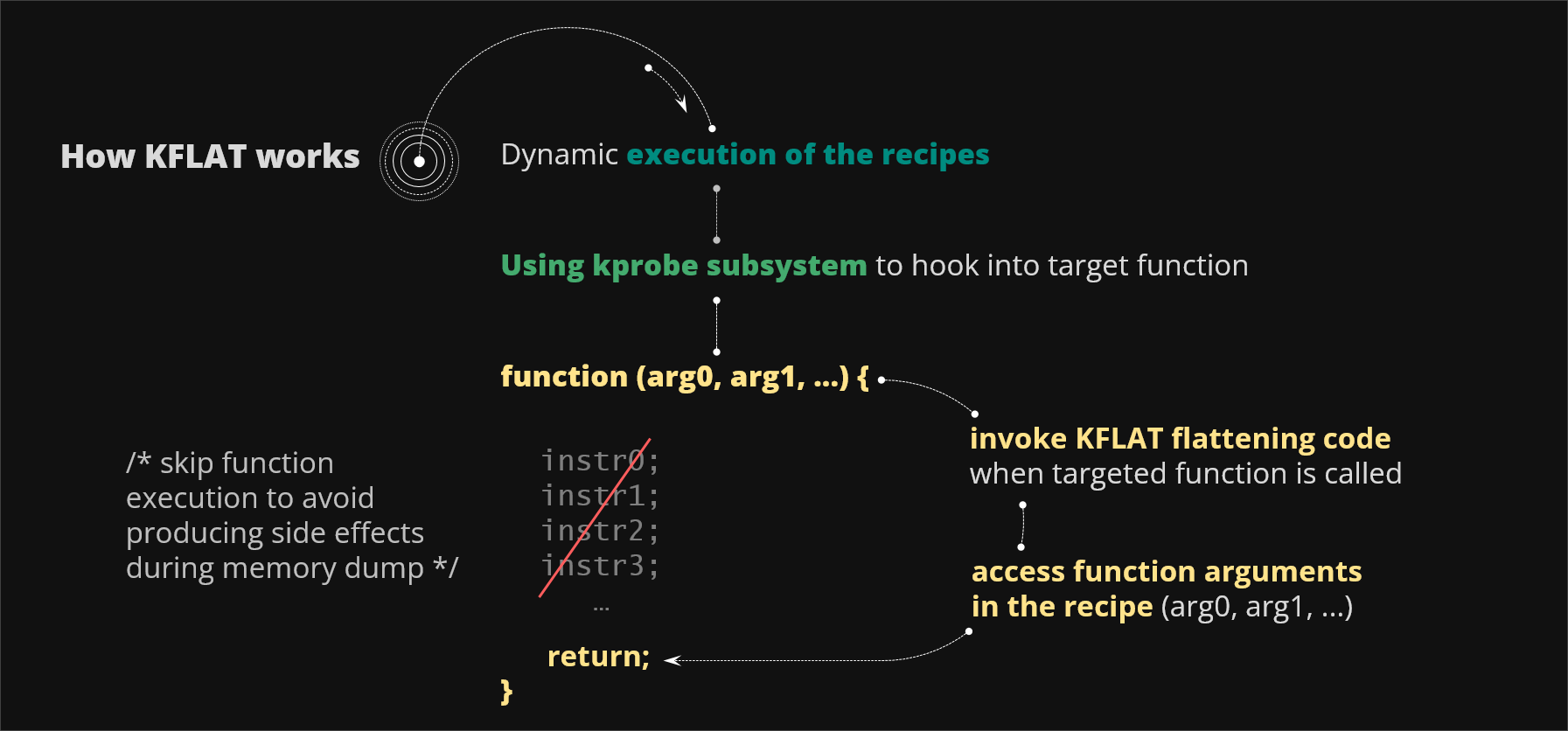
Figure 11. KFLAT hooking and recipe execution
Once you load KFLAT module into your system you can start dumping memory. You first arm KFLAT by choosing variable located within your target function and invoking this function somehow from the user space. You can do this by calling a syscall or sending some netlink packet or maybe performing some hardware interaction. Using kprobe subsystem KFLAT hooks into the function and intercepts its core registers. After that it invokes the flattening engine directly. At this point KFLAT follows the provided recipes and dumps the memory from the context of this function having access to stack variables, globals and also the heap. Basically KFLAT can see the kernel memory in exactly the same context as the original function would see. Finally you can optionally (through the special switch available to the user) skip executing the function body to avoid causing any side effects in the running systems.
During the flattening process some exceptional situations may arise.

Figure 12. Example of flattening the invalid pointer
The most common problem that you may come across is encountering invalid pointers. Whenever KFLAT is dumping structure memory and following its pointers it can encounter null pointers, user space pointers, possibly input/output memory as well as wild pointers - bacause some fields within the given structure can be unused or uninitialized. The KFLAT engine has to somehow detect this kind of situations to avoid causing kernel fault at any cost.
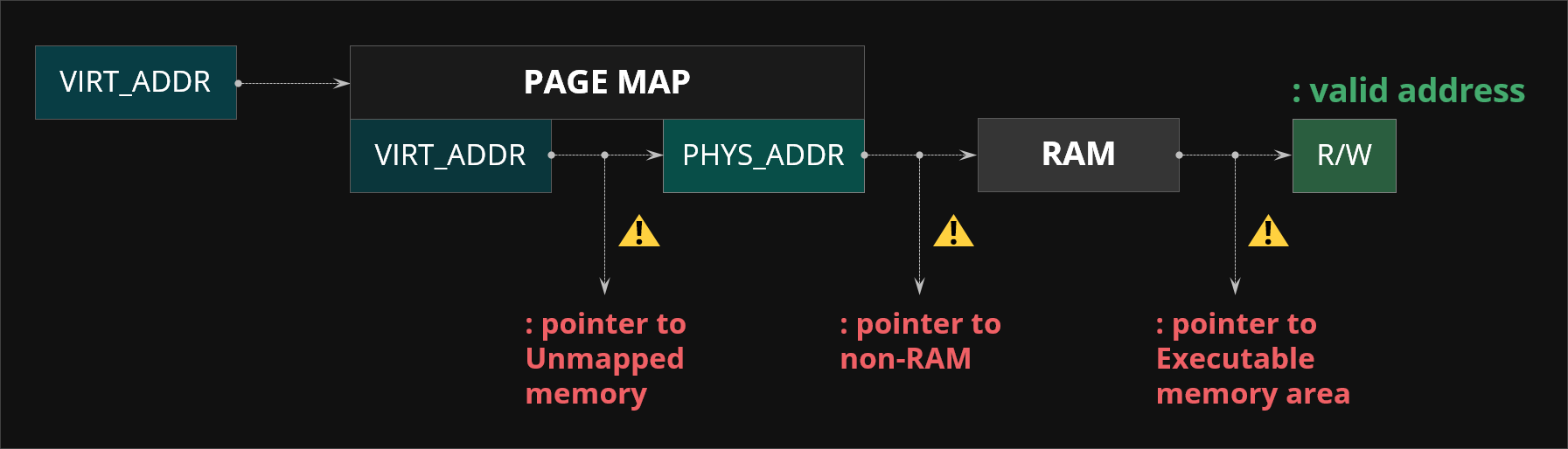
Figure 13. KFLAT page table walking to handle invalid pointers
Kflat solves this problem by page table walking. More specifically for each pointer that KFLAT encounters it translates its virtual address into the physical address using page tables just like normal CPU does and then it checks whether the physical address is pointing to the RAM memory. Finally it checks whether this memory is readable to ensure it dumps only the memory that is holding some data (and not e.g. any code assembly that isn't portable in any way). This approach in contrary to relying on page fault handlers allows KFLAT to detect whether the target pointers point to RAM (to avoid dumping memory that is for instance mapped input output memory to which accesses could alter the system state or even cause a system crash).
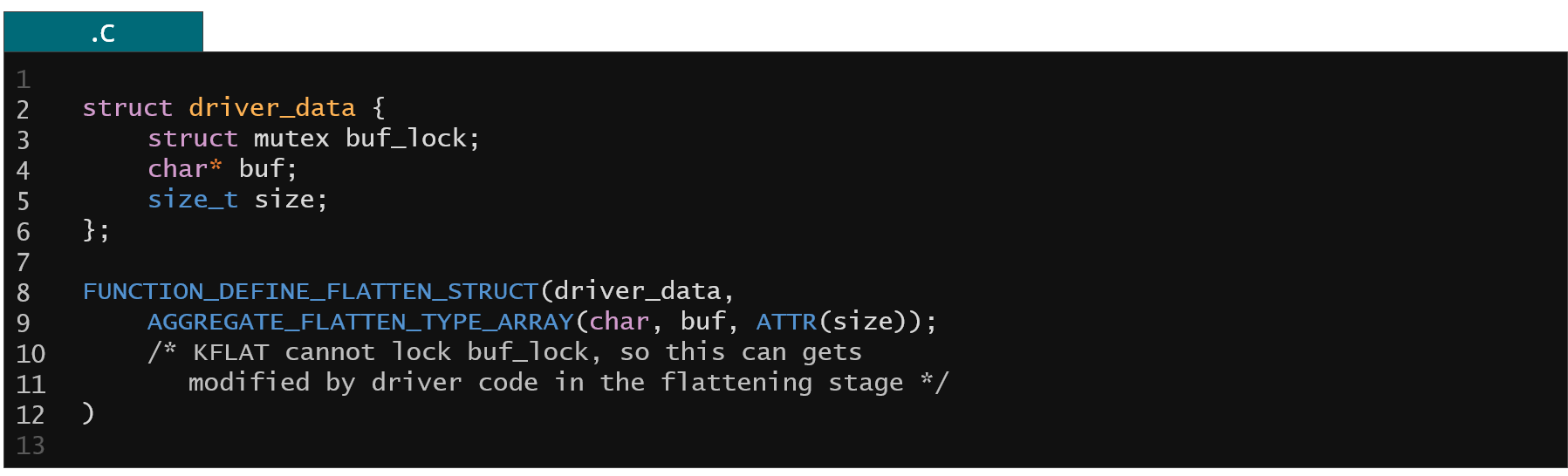
Figure 14. Example of KFLAT potential data races
Another problem that KFLAT needs to handle is data races. Many kernel structures inside the kernel are used concurrently, synchronized by various primitives like mutexes, semaphores or spin locks. During the process of memory dump KFLAT cannot lock all of these primitives since it could cause global system deadlock. What KFLAT does in this case is a bit straightforward and brutal, i.e. it can (optionally) use stop machine to basically freeze all other tasks in the system. Doing so it can create a memory snapshot from some specific moment of the kernel operation. If user needs to access the kernel structure that is heavily used and wants to ensure that the memory is complete he can also specify the mutexes to be locked within the KFLAT recipe itself.
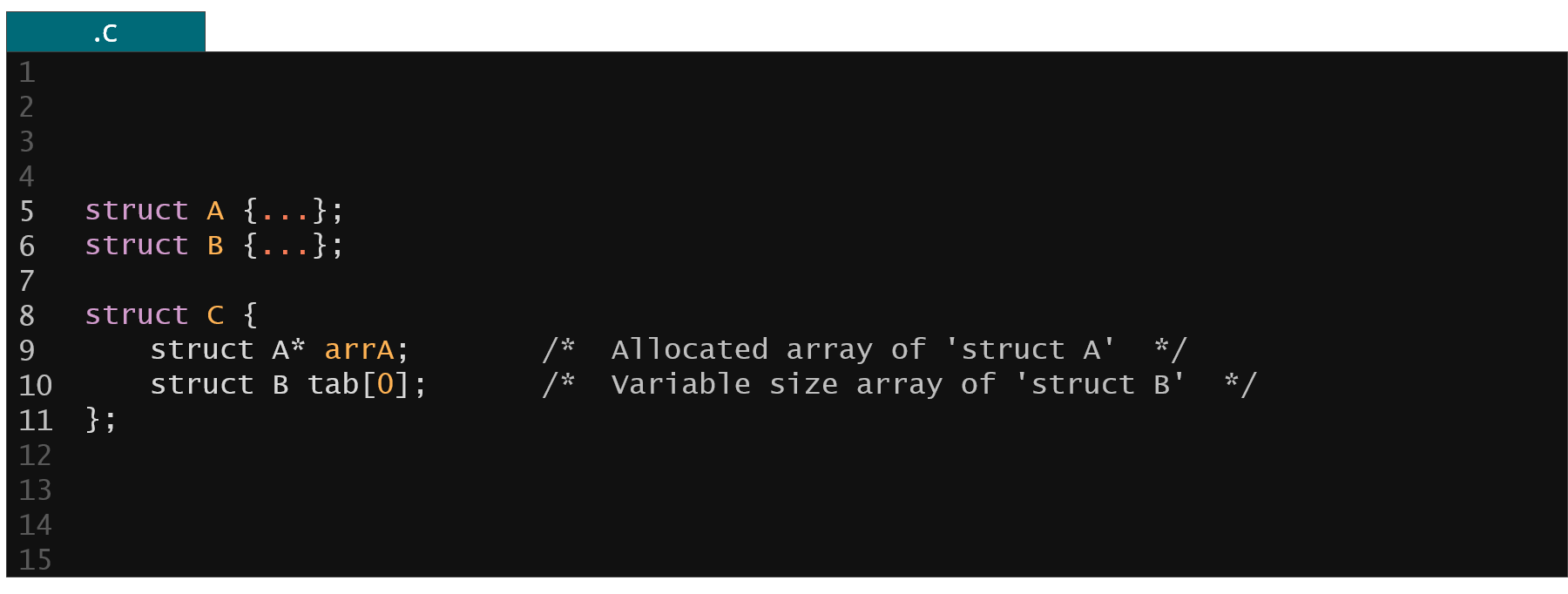
Figure 15. Example of KFLAT unknown array sizes
Kflat also have to handle unknown array sizes. Inside the kernel you can often see zero size arrays or pointers to integers or other structures that are of unknown size. It is also not always obvious what is the size of this object based solely on the static analysis of the code. For such cases KFLAT supports extraction of allocation metadata from slab allocator.

Figure 16. Example of dedicated recipes to handle unknown array sizes
When unsure what's the target array size you can ask the slab allocator (through the AGGREGATE_FLATTEN_DETECT_OBJECT_SIZE or AGGREGATE_FLATTEN_STRUCT_FLEXIBLE recipes) to provide you with the necessary information about allocation size and to dump the whole array of objects even if you don't know what is the actual size at compile time.

Figure 17. Example of dedicated recipe to handle function pointers
Finally a very common pattern in the kernel is embedding of function pointers inside the structures data. For example struct file_operations instances are very commonly used in the kernel to implement Linux kernel driver interfaces. It therefore stores a lot of function pointers to specific function handlers that implements specific driver functionalities. In KFLAT we cannot obviously dump the targeted memory pointed to by these function pointers since this would be the binary code of the Linux kernel executable (which cannot be used on the other machine, possibly with different architecture) in a new virtual address space.
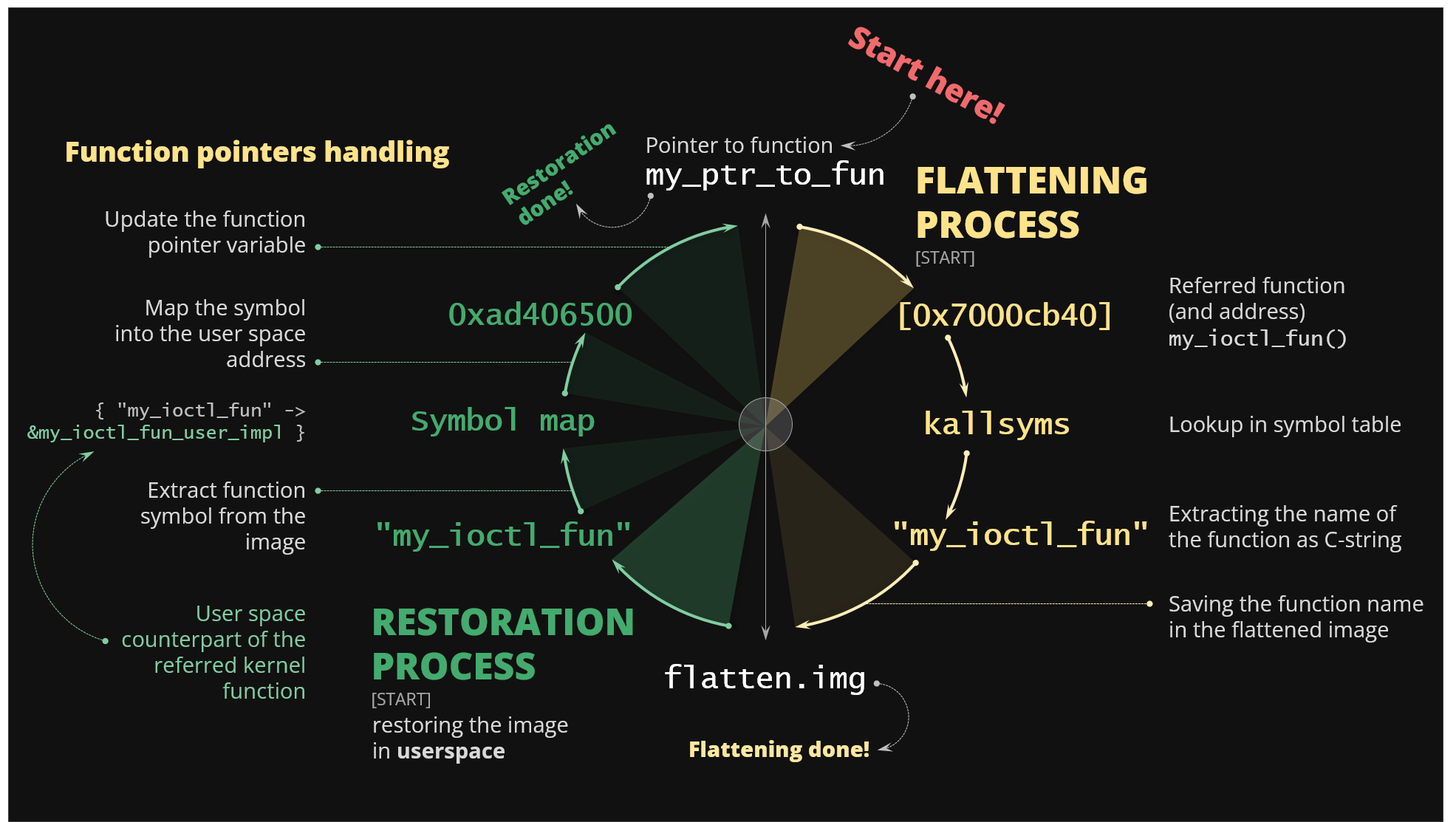
Figure 18. The process of flattening and restoration of the function pointers
In that case KFLAT uses kallsyms to convert a specific function pointer into function name and saves it into the flattened image file. During the restoration phase it expects the user to provide it with a map that will convert this function name into some functionally equivalent function in the new address space on the other system. This can be a real function implementation or it can be some simple stub if the function equivalent is unavailable in the user application. That way it can set-up function pointers in the new address space and make them work just like they would in the original kernel.
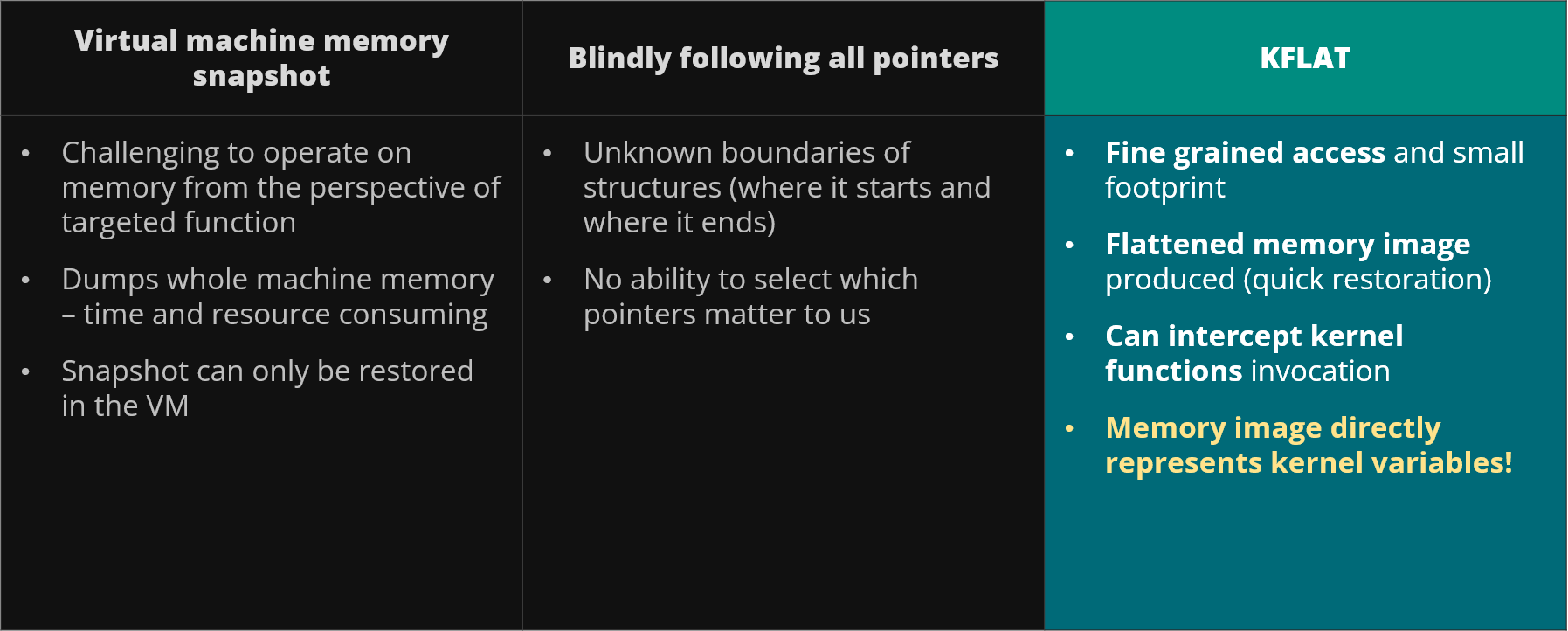
Figure 19. Other approaches to memory serialization
As you can see KFLAT is a bit tricky and somehow complicated so what about some other approaches for serialization? First of all you can try using virtual machine snapshots - basically run some kernel in the virtual machine and dump the whole machine memory. This approach has a few disadvantages. First of all it's not always easy to run the target kernel or drivers in VM, especially if they are intended to be used on some specific proprietary SoC. Furthermore getting the whole snapshot of the virtual machine memory is time and resource consuming as we can end up for instance with 8 gigabytes of memory dump. Moreover this memory will be a whole RAM memory dump so it's not easy to deduce where some structure starts or ends, for instance if you are interested in a very particular structure in the kernel it is not obvious where it is in this dump.
An alternative approach is to blindly follow all the pointers. So basically you start somewhere in the kernel memory, dump some initial kernel structure and then look for everything that seems to be a pointer (within this structure members). You can validate them whether they're correct and then you further follow everything that you can find. Well, in this approach it's not always obvious what is the size of target memory. It's also not always easy to determine which pointers actually matter to you. For example if you start dumping struct file you will then follow to the struct task_struct and then by using list_head you follow all the task_struct in the kernel. It happens that the task_struct also holds the pointers to virtual address spaces of the processes so you will end up dumping virtual address spaces of virtually every process in the system. So again you have no fine-grained access.
In case of KFLAT you can perform memory dump only of structures and their parts that are interesting to you, your flattened image is very quick and easy to restore and also you can intercept kernel function invocations so you can perform memory dump from the perspective of some function. Finally the memory images directly represent kernel variables so the very same code that have used it in the kernel can now use it in user application without any changes.
To sum up KFLAT is built as loadable kernel module so it's very easy to use on embedded systems and can be easily loaded into the running system. It provides instantaneous restoration which is perfect for fuzzing and other use cases. It also allows you to relate the content of memory dump with the original structure of the code so you don't have to use any additional API, you can just treat this restored memory like any other C memory.
KFLAT use cases
How could we use KFLAT to test the Linux kernel? Actually we asked ourselves the opposite question, what kind of tools could we implement or integrate that could help us finding software problems in the Linux kernel. And one of the answers what the Auto Off-Target project.
Figure 20. Introduction of the off-target testing technique
Imagine you have to test a piece of software that is otherwise a very difficult to test. You might have some parser embedded deep down in your WLAN driver and in order to test it you have to set up the connection. You also need to send the messages over the air so you have natural limitation in the throughput, therefore the possible fuzzing would be very slow. So you're looking for some alternatives and one of them could be an off-target testing. In this methodology you just extract the parser code from your WLAN driver and compile it on your development machine, create the executable and then just feed the messages to your parser code through this executable. In this scenario you would have all the development tools available for your disposal. So you could you gdb, you could embed coverage information, you could use fuzzers, sanitizers, valgrind, even symbolic execution is possible in that case. We assume that the parser doesn't depend on the hardware very much - it doesn't write to the CPU registers directly, it's just a portable C code that shuffles around data between buffers.

Figure 21. Creation of the off-target (OT) harness extracted from the larger system
How could you create the off-target then? You extract the main parser function and try to compile it. Probably it will fail because there are missing dependencies. What you can do now is just pull more code (missing type definitions, missing functions in the call hierarchy, missing referenced global variables) and try to compile it again. You'll probably have to do it many times until the code finally compiles. As you can see it's quite a painstaking job to do this.
Figure 22. Summary of the Auto off-target (AoT) approach
The AoT project was actually born to solve this problem. What it does it extracts the compilable off-target (OT) from some bigger system in an automatic fashion. More details can be found on the Github project page [1], you can read the paper [2] or see the talk from the KLEE Workshop 2022 [3] but the main question is how could this help us in finding software problems in the Linux kernel?

Figure 23. Using AoT to test the Linux kernel entry points
The main idea here is as follows. Maybe you could take the entry point to the kernel, e.g. some ioctl function, write, mmap etc., create an off-target from it, compile it on your development machine and just test it there. There is one problem though. When the kernel runs the ioctl function there is an entire kernel state available to it within your function but when you run it in your off-target there isn't. AoT project provides some initialization mechanism - the generated code tries to initialize all the kernel structures in the OT using some lightweight static analysis but it's not perfect and fuzzing can lead to some false positives. So how about when the kernel runs the ioctl function you just save the entire kernel state used by this function using the KFLAT tool, dump it to the file and restore it in the off-target application. You could imagine this whole process as transferring execution from the target to the host on development machine (or multiple instances of the development machines) at the point of the ioctl function entry.
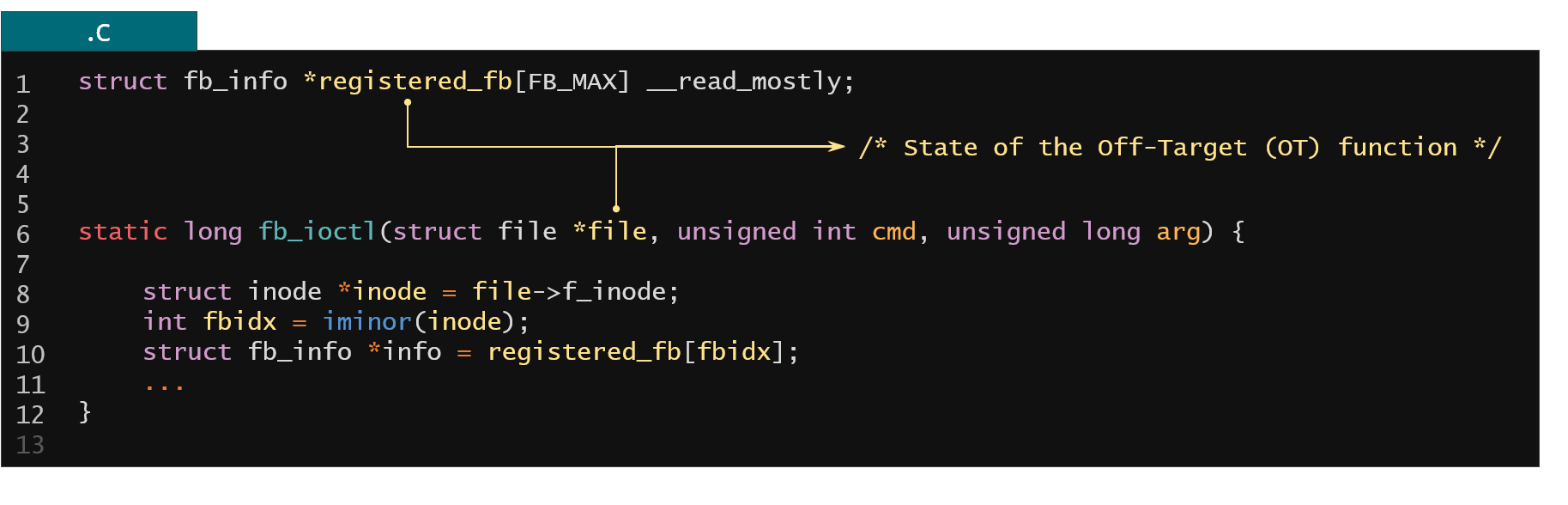
Figure 24. Example of the global kernel state used in the Linux kernel entry point
So the question now is what is the kernel state used in this ioctl function? We have the function arguments (like struct file argument which actually represents a lot of the kernel state because it's quite a big structure with lots of dependencies) and you also have global variables used in the code of our ioctl function. Those are the two things that you need to save. So how could you do it?
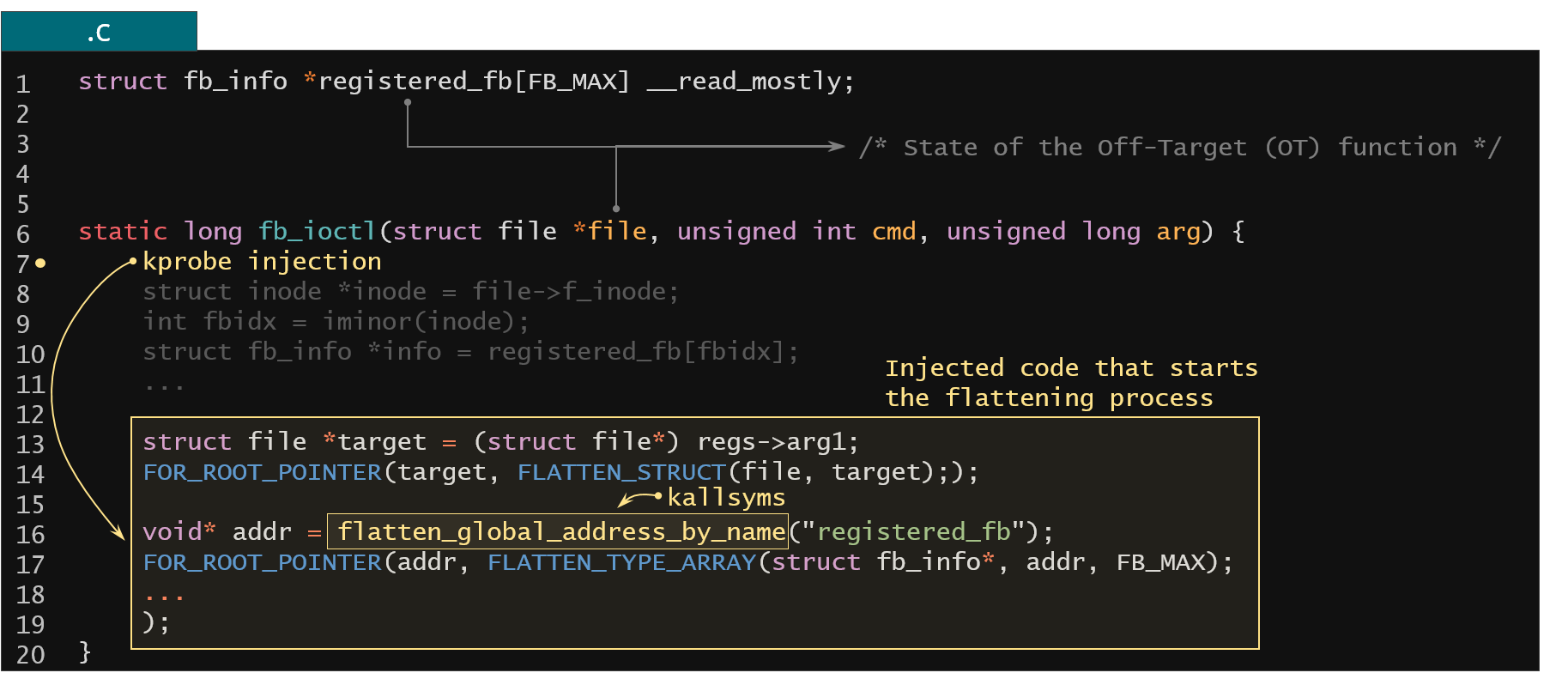
Figure 25. Flattening the global kernel state used in the Linux kernel entry point
You would just insert the kprobe injection at the entry of this ioctl function and just execute the KFLAT recipe that will do all the work. If you need to extract the addresses of global variables you could just consult the kallsyms kernel symbol table.
Initializing the part of the kernel state in the off-target was one of the possible usages of KFLAT productively. Another idea would be extracting some debug information from the running system or getting periodic snapshots of data for the system tracing purposes. Below is an example of a simple recipe that is used to dump the task_struct information from all the processes in the system.
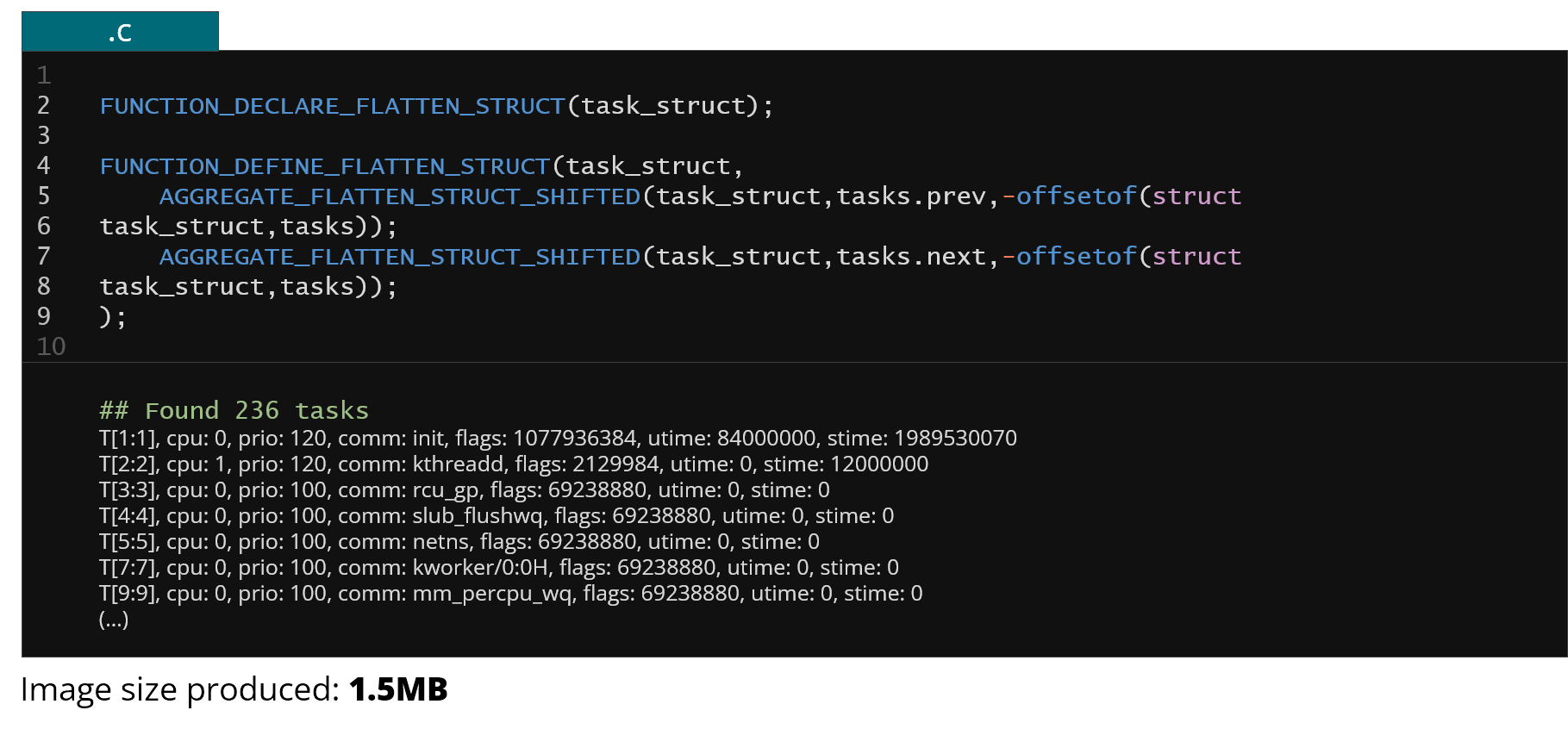
Figure 26. Example recipe to dump Linux process structure information from the entire system
Actually this is a full recipe that is needed to do this. It only follows the tasks dependency in the task_struct structure so most of the pointer dependencies are skipped but there's still a lot of non-pointer members in the task_struct that can provide you with some useful information. In the picture above there is also an example (below the recipe code) of user space application that actually reads this dump and prints some information from it (like process name, priority, CPU association etc.).
Recipe generation
Above you could see some examples how KFLAT could be used to actually help finding and analyzing software problems in the Linux kernel. Let's now dive into more details about the preparation of the recipes for the proper KFLAT operation for the Linux kernel structures.

Figure 27. Automatic approach for the generation of the KFLAT recipes for the Linux kernel
So what's the deal here? The KFLAT dump is as good as the recipes used to describe the format of the data to be saved. So you have a problem here because there's a quite a lot of kernel structures that you would need to handle. For example in the Android common kernel for the x86 there's around 15k interesting struct types that you would need to taka care of. What interesting means in this context is a non-anonymous or typedef'ed struct type used in some function or global variable. Even though half of it is trivial meaning there is no pointer data inside those structures you still need to handle around 23k pointer members and write the recipes for them. So the question is maybe you could generate those recipes? Unfortunately it's a very difficult problem to solve in general because you might encounter some edge cases that would require you to know the code perfectly well in order to write the proper recipe. That means it's very hard to automate the preparation of correct recipes for the entire type hierarchy in the Linux kernel. So maybe you could take another approach - generate all the recipes that work most of the time and just handle the edge cases by hand?

Figure 28. Code Aware Services (CAS) project that provides database of code information extracted from Linux kernel source code
So now you start thinking about writing the recipe generator. In order for this task to be successful you would require the kernel type information available to you so you could just write the application and not the full-fledged source code parser. As it turns out we already have the type information available for the Linux kernel. Last year, at the Linux Security Summit NA 2022, we presented the Code Aware Services project [4] and especially the Function/Type Database part of it (FTDB) which provides exactly what we need in the form of intermediate, easily parseable file format, like JSON file. The video from the presentation is available [5] for scrutiny, but the main point here is that there is clang based processor that extracts some interesting information from the C source code (like type information) and saves it in some intermediate format easily accessible by applications. Now having this JSON file available for the Linux kernel you can start writing the recipe generator application.
Let's now take a look what kind of problems you could encounter while trying to do this.

Figure 29. Average structure members usage across 1k Linux kernel entry points
The first problem is that as we mentioned already there is a lot of structure members that you would need to handle. Therefore there's a lot of potential for the edge cases that you could encounter. You could manage that by just focusing only on the members that are interesting to you. For example in the off-target function these would be the members which are actually used in the OT code. Like in the example above we have this fb_ioctl function and only the f_inode member of the struct file of the argument file is actually used in the body of this function (and more specifically the function call hierarchy). So maybe you could get away with it by just writing the recipe only for this specific member. The data that backups this approach is as follows. In the experiment with generating 1k off-targets from the Linux kernel entry points, when we focus only on the used members, on average there's only around 10 percent of members actually used of all the defined members in the relevant source code.
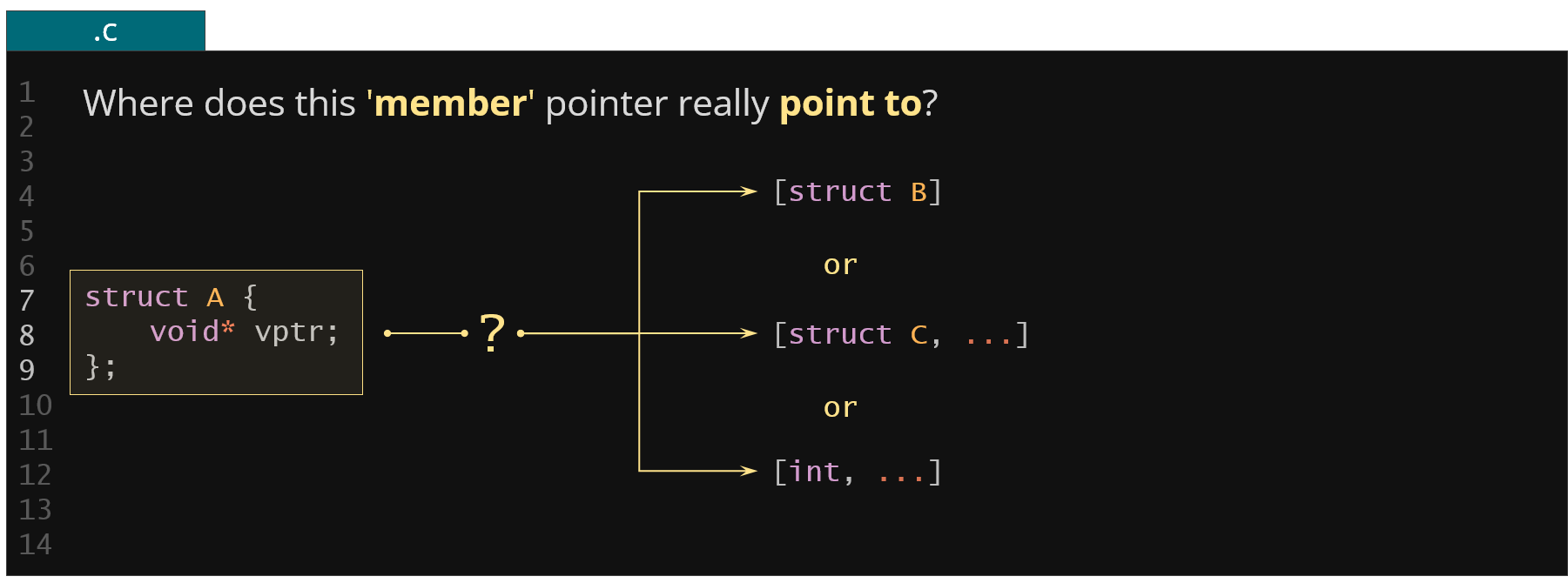
Figure 30. Example of a void* member type ambiguity
Another set of problems is related to the polymorphic nature of the structure members. For example for the member vptr from the example above, where does this actually point to? Is it a struct B or maybe some array of integers? You cannot easily know it at the first glance on the code. What you could do here is to implement some kind of static analysis of the code and just look for all the expressions where this void pointer member was actually used. Maybe you could deduce the type it points to based on this analysis.

Figure 31. Example of void* type resolution through static analysis
What you could analyze are the assignment expressions, initializations, direct casts, passing to function, return from function etc. This static analysis could still give you some ambiguous results and in that case you would need to intervene manually but in a lot of cases it actually gives you one proper type that you're looking for.
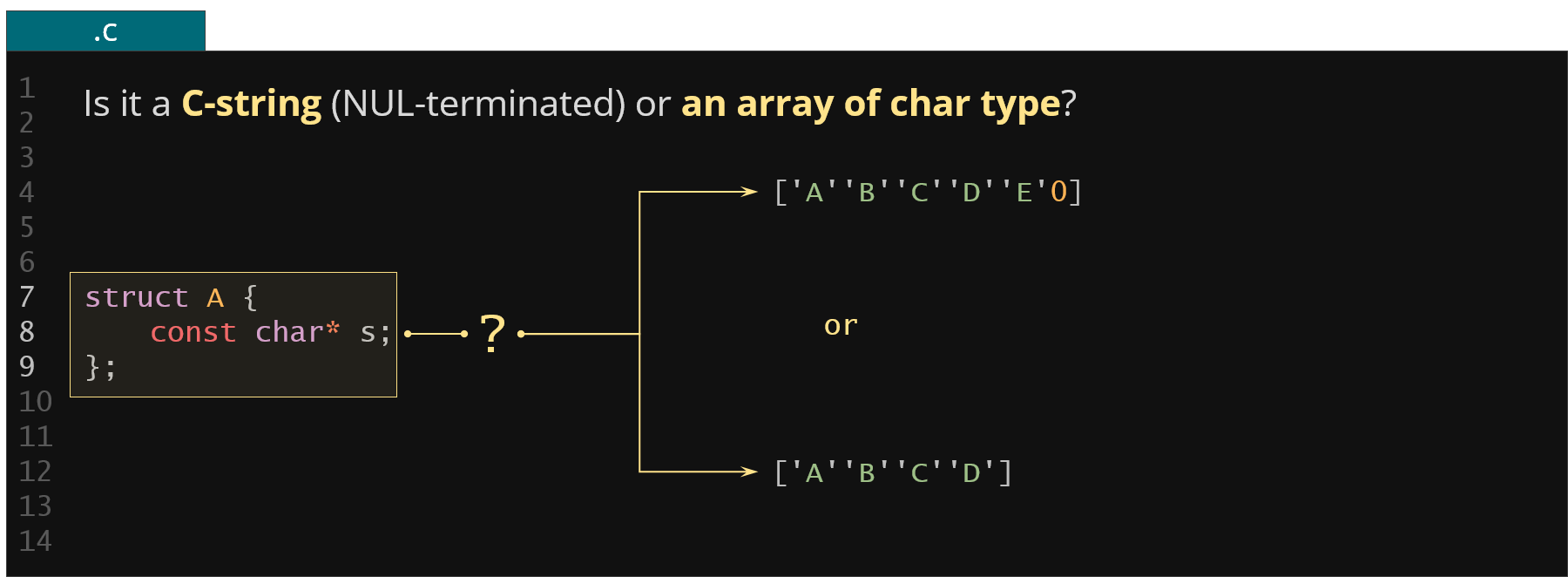
Figure 32. Example of a character pointer member type ambiguity
Another problem is related to the character pointers as depicted above. Does the s point to a C-string (i.e. an array of characters terminated by the 0 byte) or it points to an array of characters of specified size?

Figure 33. Example of C-string type resolution through static analysis
What you could do here is just take the member s and check whether it was passed to some functions that we know takes the C string as an argument (like strlen). If it does we can deduce that our member is the actual C-string because otherwise our original kernel code would fail when executed. This way we could find all the members that we are sure are C-strings. For the rest of members some additional static analysis (or manual inspection) step would be needed to determine the potential size of the character array.

Figure 34. Example of member array size ambiguity
Let's now take a look at another potential problem, i.e. the member pK. Is it pointing to a single element of struct K or an array of elements of struct K?

Figure 35. Example of member array size resolution through static analysis
What we could do here is to check all the dereference expressions of our member pK to verify whether there is a dereference offset different than zero used in any of these expressions. If not we could deduce that the pK is pointing to a single element of the potential array (we would also need to verify if the pK is not used at the right-hand side of any assignment or initialization expression so its value was not copied to any other pointer variable which could be then potentially used with a dereference offset different than zero).
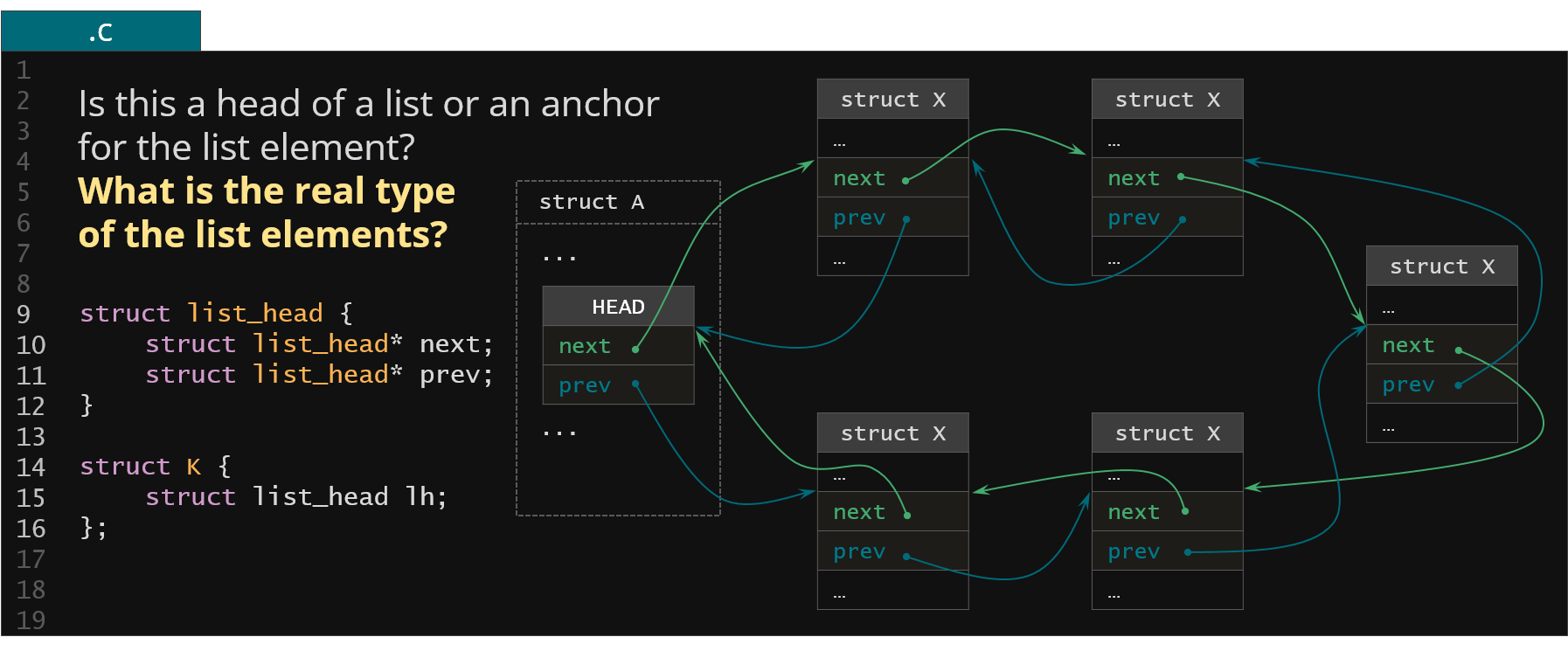
Figure 36. Example of the type ambiguity in the Linux kernel list implementation
In the final example presented above we could see the brilliant pattern of the Linux kernel list implementation. What we got here is a list of the Linux kernel elements linked together using the struct list head objects. There are two challenges here when it comes to the memory serialization. The first challenge is that when we have a list_head member, is it a head of a list (meaning pointing to the first and the last element of this list but not being the actual list element) or do we have the anchor (meaning it's embedded into other structure and this particular structure object is the actual list element)? The second challenge is that we have to conclude what is the actual list element type for the anchor elements.
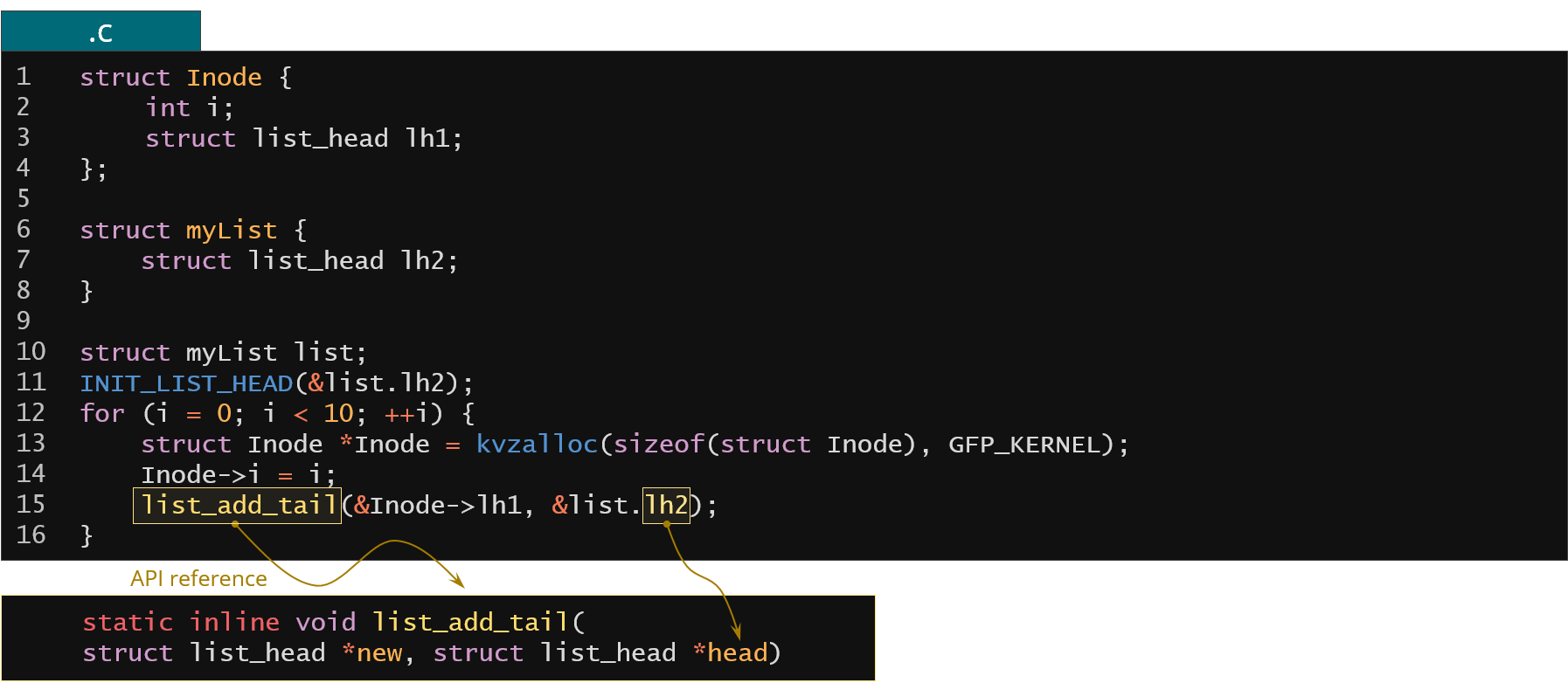
Figure 37. Resolving head members in the Linux kernel list implementation through static analysis
So how to find the heads? One way would be to check all the invocations of the Linux kernel list API and just match the arguments passed to these functions with the parameters that takes the head. For example in the code above we have the lh2 member which is passed to the list_add_tail list kernel API function as a second argument. In the kernel API reference for this function the second argument is the head so we conclude that lh2 is the actual head of a list. And how could we find what is the actual type of the list element? Again, we look for some functions in the list kernel API that actually extracts the element type from the anchor.
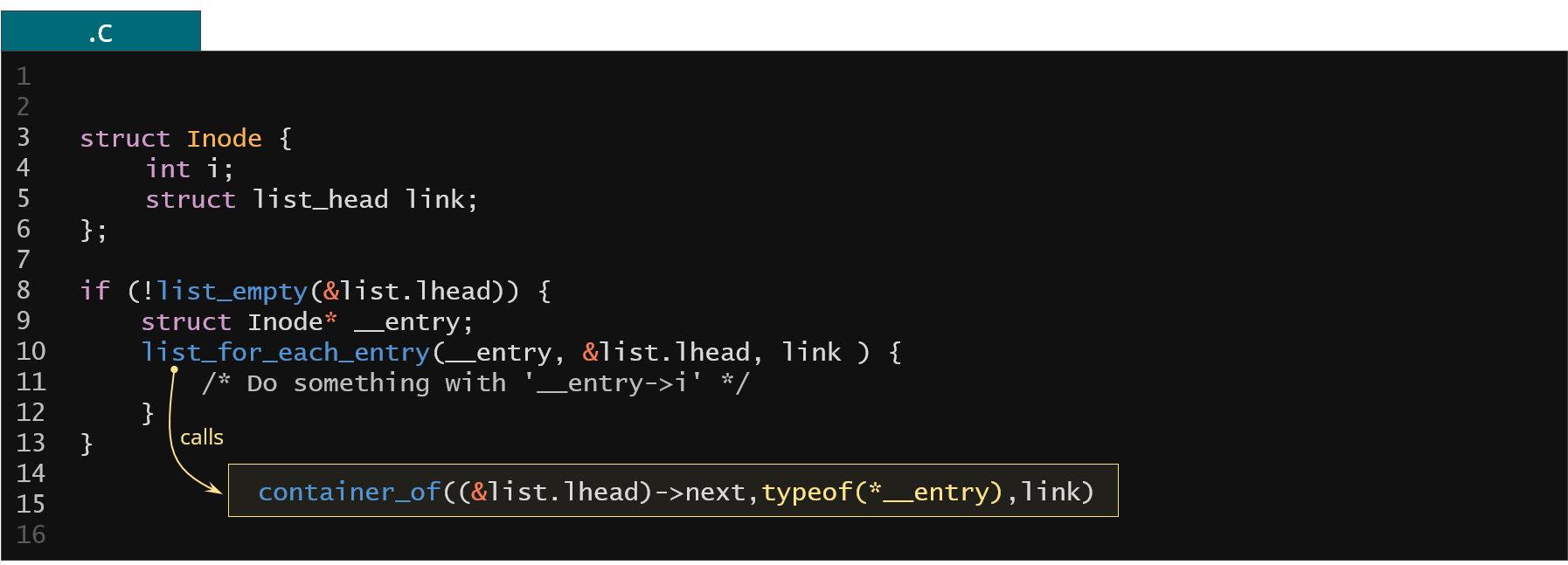
Figure 38. Resolving list element type in the Linux kernel list implementation through static analysis
For example in the code above we have list_for_each_entry which calls the container_of under the hood. This is exactly what we're looking for because the second argument passed to the container_of is the actual list element type (based on that we conclude that the anchor link actually translates to the struct Inode list element type). Now, when we have the head and the proper list element type we can just walk the entire list one by one and serialize it using the properly generated recipes.
In summary we can apply various static analysis techniques to improve the generation of recipes for the Linux kernel structures.
One more thing worth to mention regarding the recipes is the potential problems that you may encounter while trying to compile those recipes. Here we have the remainer of the recipes from the simple example from the beginning of this article.

Figure 39. KFLAT recipes from example from Fig. 2
As you can see the recipe makes references to the members by name (e.g. pB). In order for this recipe to compile successfully you would need to include the full type definition of the involved structures because the compiler needs to compute the offsets for all referenced members. This might be a problem when you're writing a recipe for a structure which is defined privately in some C file because you cannot easily include a C file in your code.

Figure 40. KFLAT recipes from example from Fig. 2 dedicated for types defined privately in C source files
The KFLAT helps you with that by providing a family of so called self-contained family of recipes where it is your job to provide all the offsets of the members in your structure and also the structure size. In that case you don't need to include the type definition of the structure you're writing recipe for. The problem is that you'll need to compute all the offsets by hand. On the other hand this functionality is mainly dedicated for the recipe generator so probably it wouldn't matter to you in most of the cases anyway.

Figure 41. Example of type with very difficult case for automatic recipe generation
Finally even if you have this very well working recipe generator backed up with some advanced static analysis there still might be cases where it won't work properly like in the example above. Are we using the void pointer member here so we have to follow the dependency or we're using the unsigned long value and it's enough to just copy the data? The information which member of an union is currently used can be spread around different structures and might not be easy to compute. These kind of edge cases would probably require some insight and help by the people who are responsible for the development of a specific module in question. Furthermore even if you write a recipe for your own structure type in your own driver you still can end-up having some common kernel structures in the dependencies. In that case you could still end-up writing recipes for a common kernel structures again and again. What would be highly beneficial here is that if we have this kind of library of KFLAT recipes written or reviewed by experts for common kernel structures. This library could be then included and used in the code while writing recipes for the common kernel code.
UFLAT
Everything we said so far about serialization of the variables was done inside the kernel but the same principles and the same algorithm could be applied to the user space memory as well. In that manner we could easily extend KFLAT to serialize the variables from the user space process. For example you might have some user space process which reads or computes a lot of data before it actually starts doing somethig useful. Very good example (as depicted below) might be a very big build system which reads and parses lot of makefiles before it gives you some very small incremental build. What you could do here is to prepare the snapshot in the memory of all the parsed makefiles, save it to the file and when you run the build again - assuming the makefiles didn't change - you could just read those in a matter of milliseconds.
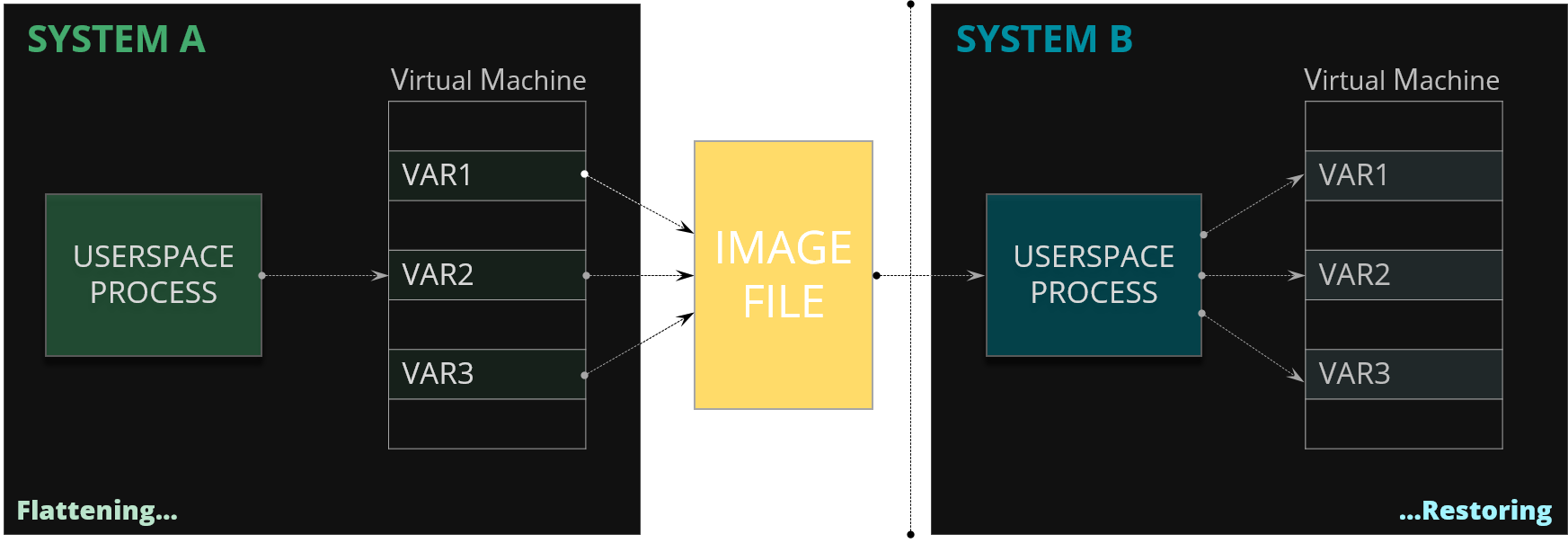
Figure 42. KFLAT operation on the process memory in the user space application
Summary
To summarize, KFLAT can serialize Linux kernel variables with their dependencies. It's built as a loadable kernel module so it's easy to use even on the embedded systems. You can restore the image very quickly and you can relate the content of the dump with the corresponding source code structures. It can be used as a state initialization for the Linux kernel code. You have to write the recipes to make a proper dump. You can generate those recipes types but you might encounter edge cases that you would need to fix by hand. It can be easily extended to the user space and you are the one who can find a new ways of using it!
References
[1] AoT: Auto off-Target @ Samsung Github
https://github.com/Samsung/auto_off_target
[2] Tomasz Kuchta, Bartosz Zator
Auto Off-Target: Enabling Thorough and Scalable Testing for Complex Software Systems
https://dl.acm.org/doi/10.1145/3551349.3556915
[3] CAS & AoT: Enabling Symbolic Execution on Complex System Code via Automatic Test Harness Generation
https://www.youtube.com/watch?v=Xzn_kmtW3_c
[4] CAS: Code Aware Services @ Samsung Github
https://github.com/Samsung/CAS
[5] Code Aware Services in the Service of Vulnerability Detection
https://www.youtube.com/watch?v=M7gl7MFU_Bc&t=648s